

新闻资讯
拥抱变化,赋能产业互联时代
浅析Sora
2024-02-27
Sora,美国人工智能研究公司OpenAI发布的人工智能text-to-video模型,于2024年2月15日正式对外发布。Sora这一名称源于日文“空”,即天空之意,以示其无限的创造潜力。目前的视频数据生成模型主要分为三种网络模型:生成式对抗网络、自回归transformer和扩散模型,这些网络模型主要关注于在短视频且尺寸固定的视频,而Sora是能够跨时间空间,不同纵横比和分辨率的一分钟高清视频,相对于之前的网络模型性能上有了极大的提升。
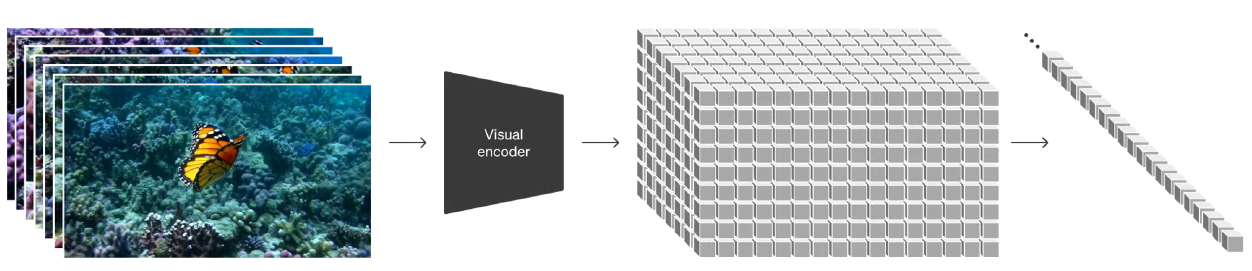
其主要架构是基于时空块(W、H、T三个维度的切块)隐编码(latent codes)之上的transformer架构。隐编码就是从像素转换到了压缩域,也叫隐空间,主要是降低计算复杂度。其工作原理是将视频压缩到更低维度的隐空间,之后再把其表示分解成时空块。
视频压缩网络是作为编码器用来减少视频数据维度,该网络可以将原始视频直接作为输入,输出一个隐式表达在时间和空间上。之后Sora将会在压缩过的隐空间上进行训练和视频生成。除了视频压缩网络,其还训练了一个对应的解压缩网络模型,能够把生成的隐编码映射还原到像素空间。Sora是一个diffusion transformer模型,将输入的噪音块还原成干净的块。

在Sora之前生成视频通常是将视频缩放裁剪到一个固定的分辨率,例如256×256。而Sora能够将分辨率在1920×1080横屏和1080×1920竖屏之间的视频作为样本输入,从而获得更好的性能。从结果上来看,使用原始视频的分辨率作为输入能够有效的改善构图和框架,而使用经过裁剪的视频作为输入,有时会导致输出视频仅显示部分主题内容。

此外,实验结果表面,训练一个text-to-video生成式系统,需要的视频数据集应当包含字幕信息,这样能够生成更高质量的视频内容。因此openAI团队在训练了一个高度描述性的字幕模型,用来生成原先视频数据集的字幕信息。最后还利用GPT将用户输入的简短提示词扩展为更为详细的视频内容提示词输入给Sora,使得生成的高质量视频能够更加准确的符合我们想要生成的视频内容。
简单的总结,Sora=Magvit+DiT+NaViT+Video Caption。Sora是采用了Meta的 DiT框架,融合了Google的 MAGViT的Video Tokenize方案,借用Google DeepMind的NaViT支持了原始比例和分辨率,使用OpenAI DALL-E 3 里的图像描述方案生成了高质量Video Caption(视频描述)。