

新闻资讯
拥抱变化,赋能产业互联时代
飞跃!40系架构深度解析
2023-07-25
RTX 40系列在架构、技术上有了极大的突破,这一代的Ada架构和上一代的Ampere架构又有哪些不同,今天就让我们以GeForce RTX4090的视角进行阐述,后续过程中我们将GeForce RTX 4090简称为4090。
4090芯片架构图如下图1所示,其是以Ad102为基础,阉割其中的一块图形处理集群(Graphics Processing Cluster,GPC)和两块纹理处理集群(Texture Processing Cluster,TPC)所形成。左右两侧的共有12个Memory Controller,用来控制显存位宽,每个Memory Controller代表32bit的显存位宽,因此4090的显存位宽为32×12=384bit。GeForce RTX 4090使用21Gbps的GDDR6X显存颗粒,这里的21Gbps可以看做等效频率21GHz,带宽=频率×位宽,因此可以得出4090的带宽为21×384=8064Gbps,而1Byte=8bit,因此单位转换一下就有8064÷8=1008GB/s,得出我们常见的带宽单位形式,4090的带宽为1008GB/s。

图1 Ad102芯片架构图
在底层芯片架构图中,我们首次看到了光流加速器单元(Optical Flow Accelerator, OAF),这个是这个单元是为了DLSS3.0技术所创造出来的,在后续的文章中将会进行介绍。其次,NVIDIA首次将编解码单元NVDEC和NVENC单元展示在了芯片底层架构中,说明了其对编解码性能的重视,也许是为了打击友商的产品。在40系列之前,GeForce系列显卡的编解码单元基本为一个编码单元和一个解码单元,除极个别显卡例外。在40系列部分显卡中将编码单元的数量提升到了两个,增强了显卡的编码性能。除此之外NVIDIA对编码单元进行了升级,现在是第八代NVENC,相比上一代新增了AV1编码能力,而解码器却并没有升级,还是第五代的NVDEC,其本质原因是因为解码单元的能力远大于编码单元的能力。详细的编解码单元信息可以查看Video Encode and Decode GPU Support Matrix。NVIDIA GPU支持ffmpeg编解码硬件加速,相关的基本显卡性能测试可以查看Using FFmpeg with NVIDIA GPU Hardware Acceleration,目前最新的NVIDIA Video Codec SDK版本为12.1。FFmpeg作为目前视频播放器的基础架构,对视频流处理感兴趣的也可访问FFmpeg官网下载相关资料。
可以看到在4090底层芯片架构中堆叠最多的模块就是GPC单元,公有11个,GPC单元如下图2所示。每个GPC就相当于一个小型的GPU,底层GPC单元越多,说明这款显卡的CUDA核心也越多。一个GPC由6个TPC、一个光栅引擎和2个光栅操作分区组成。图2底部的有2个光栅操作分区,每个光栅操作分区由8个光栅处理单元(Raster Operator Units,ROPs)组成,光栅单元主要处理光线、反射、烟雾等效果。因此4090的ROPs数量为11×2×8=176个。一个TPC中又有两个流多处理器单元(Stream Multiprocessor,SM),因此我们也可以得到4090的SM数量为11×12-2×2=128个,其中减去4个SM是因为4090少2块TPC单元。
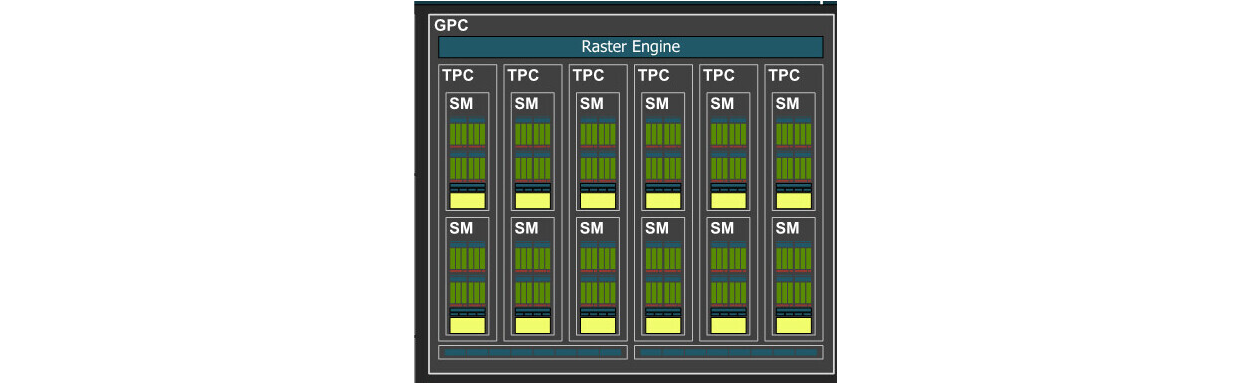
图2 图形处理集群
SM作为GPU最为重要的部分,如下图4所示。SM版本的变化就代表着GPU硬件技术的迭代,其数量多少就代表着GPU的性能的强弱。SM的版本号又被称为Computer Capability,可以在Your GPU Compute Capability中查询到你想要了解的GPU的SM版本号。 Compute Capabilities 分为5.x,6.x,7.x,8.x and 9.0 等,在官方文档中表示5代表Maxwell架构,6代表Pascal架构,7代表Volta架构,8代表Ampere架构,9代表Hopper架构,耶你没看错,Ada Lovelace架构去哪了。30系列显卡的Computer Capability为8.6,而最新40系列的Ada架构的Computer Capability为8.9,这很尴尬。下图3是截取了Compute Capabilities官方文档的一部分,从其中的文字描述中就能够了解到,Computer Capability 8.9中有128个FP32核心,2个FP64核心,还有第四代Tensor核心,没错这就是40系显卡的SM版本号。那么从上述中我们还可以得到一个信息,就是每一代GPU的SM版本都是一致的,那么只要去数SM的数量就能了解GPU的性能强弱,并且专业显卡NVIDIA Quadro和NVIDIA RTX系列的Computer Capability和GeForce系列显卡是对应一致的,所以硬件算力性能上没有区别,只是在一些软件的使用上做了区隔。还有一点就是Computer Capability是SM的版本号,不要和CUDA版本混淆了,CUDA 10、11、11.8等代表的是CUDA软件平台的版本号。

图3 Computer Capability部分官方文档
那么我们继续来看一下40系列的SM内部组成,上半部分被划分成了4块,每块的内容相同,下半部分是第三代RT核心,以及4个纹理单元(Texture Mapping Units,TMUs)。可以看到每个SM的FP32核心的数量为32×4=128个,因此4090有128×128=16384个FP32核心,值得一提的是每个SM中的64个FP32核心也能够被作为INT32核心使用,因此SM的INT32核心的数量也就可以看做是64个。算力值=GPU核心频率×核心数×2,而已知4090睿频为2520MHz,因此4090的FP32算力值为2520×128×128×2=82575360MFLOPS,换算一下就是82.58TFLOPS。4090的INT32的算力值就是FP32的一半41.29TOPS,而在此之前提到每个SM中有2个FP64核心,其数量就是FP32核心的1/64,那么4090的FP64的算力值就是FP32的1/64即1.29TFLOPS。在这之后就是第四代Tensor核心的数量为4×128=512个,第三代RT核心的数量为1×128=128个。

图4 SM单元
Tensor核心能够进行FP16、BF16、TF32、INT8和INT4等计算,而这里的Tensor核心数量是计算不出相应的算力值的,这里的Tensor核心也没有太大意义,因为NVIDIA把这里的Tensor核心做成了一整块的样子,其内部实质还是由一块块小的Tensor核心组成的,从Volta GV100后的架构图中就把这部份用一整块来盖住了,建立护城河是吧,GV100的SM如下图5所示。想要知道Tensor核心的对应精度的算力值需要通过查看相关型号显卡的白皮书中获得,或者通过白皮书中的值反推一下就能得到全系列的算力值,具体的推导过程将在后续的文章中进行说明。如果你还想了解关于4090的一些基本参数,可以访问TECHPOWERUP官网查看。

图5 GV100的SM单元